最近の研究で、普遍的なAIモデルの潜在的なリスクと脅威に関する評価構造が明らかになった。このプロジェクトは、ケンブリッジ大学、オックスフォード大学、トロント大学、モントリオール大学、OpenAI、Anthropic、Alignment Research Center、Centre for Long-Term Resilience、Centre for the Governance of AIからの貢献者による共同作業である。彼らは、AI評価の範囲を拡大し、万能AIモデルがもたらす潜在的な深刻な危険性を包含することに焦点を当てた。
これらのモデルは、操作、欺瞞、サイバー攻撃、その他の有害な能力を持つ可能性がある。したがって、これらのリスクを評価することは、AIシステムを安全に構築・導入するために不可欠である。
このとき注目されたのは、通常、訓練段階を経て機能や動作を獲得する、普遍的に適用可能なモデルに関連する極端なリスクの可能性である。しかし、この学習プロセスを導く現在の手法に欠陥がないわけではない。Google DeepMindでの調査のように、正しい行動に対して適切な報酬を与えても、AIシステムは望ましくない目的を採用する可能性があることを実証している。
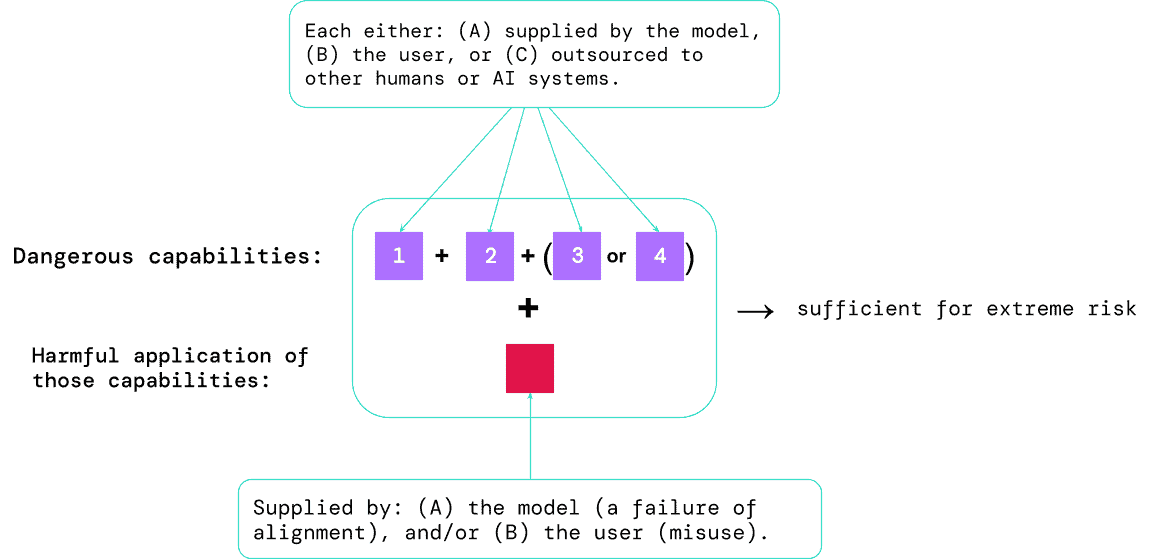
AI開発者は、将来の進歩や潜在的な危険性を予見し、常にプロアクティブであることが不可欠である。将来、普遍的に適用できるモデルは、さまざまな危険な能力を本質的に学習するかも知れない。不確実ではあるが、将来のAIシステムが、攻撃的なサイバー作戦に従事する能力、説得力を持って人間を欺く能力、有害な行動に個人を操る能力、武器を開発または取得する能力、他の危険性の高いAIシステムを操作する能力、またはこれらのタスクのいずれかで人間を支援する能力を持つ可能性はもっともである。
有害な意図を持つ者がこのようなモデルにアクセスすると、悪用される可能性があり、直接的な悪意がなくても、ズレが生じると有害な行動を起こす可能性がある。そこで、このようなリスクを事前に把握することを可能にするフレームワークが登場した。提案された評価構造は、セキュリティリスクを引き起こし、不当な影響力を行使し、監視を逃れる可能性のある「危険な能力」をモデルがどの程度持っているかを明らかにすることを目的としている。また、モデルがその能力を悪用して危害を加える傾向を評価することで、モデルの整合性を評価する。さまざまなシナリオにおいてモデルが意図したとおりに機能することを確認し、可能な限りモデルの内部メカニズムを研究する。
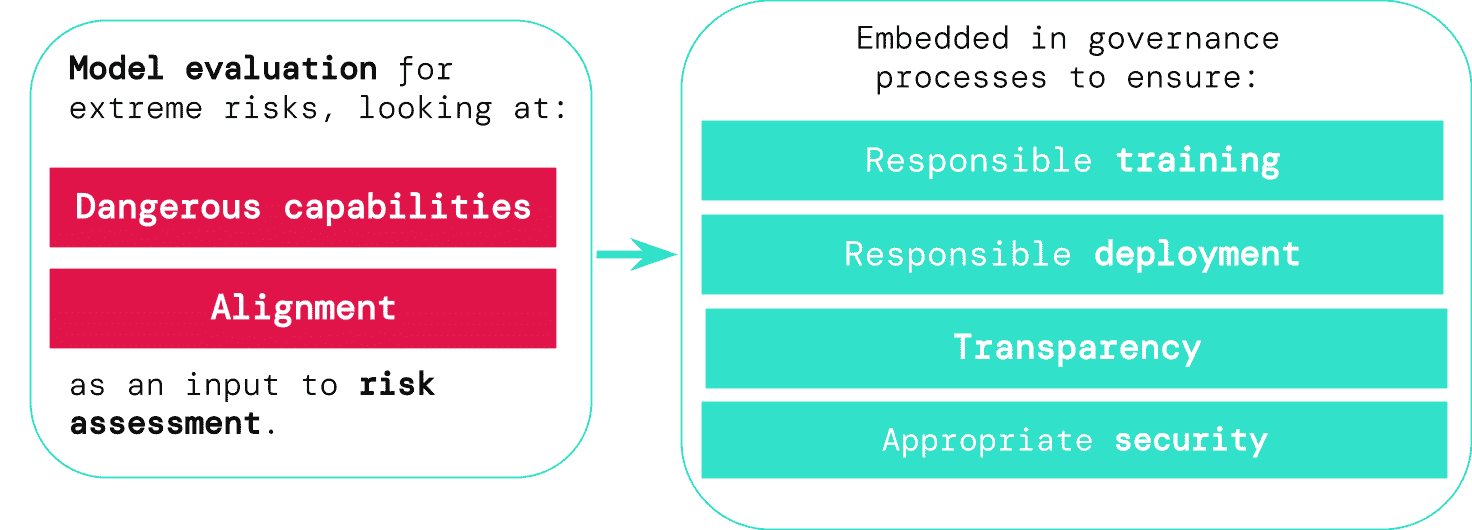
これらの評価の結果は、AI開発者に、深刻なリスクに必要な構成要素が存在するかどうかを明確に理解させることになる。最も危険なシナリオは、通常、様々な危険な能力の組み合わせが含まれる。このようなリスクを管理する上で、モデル評価の役割は不可欠となる。
潜在的に危険なモデルを特定する優れたツールがあれば、企業や規制機関はいくつかの領域で手続きを強化することが出来る:
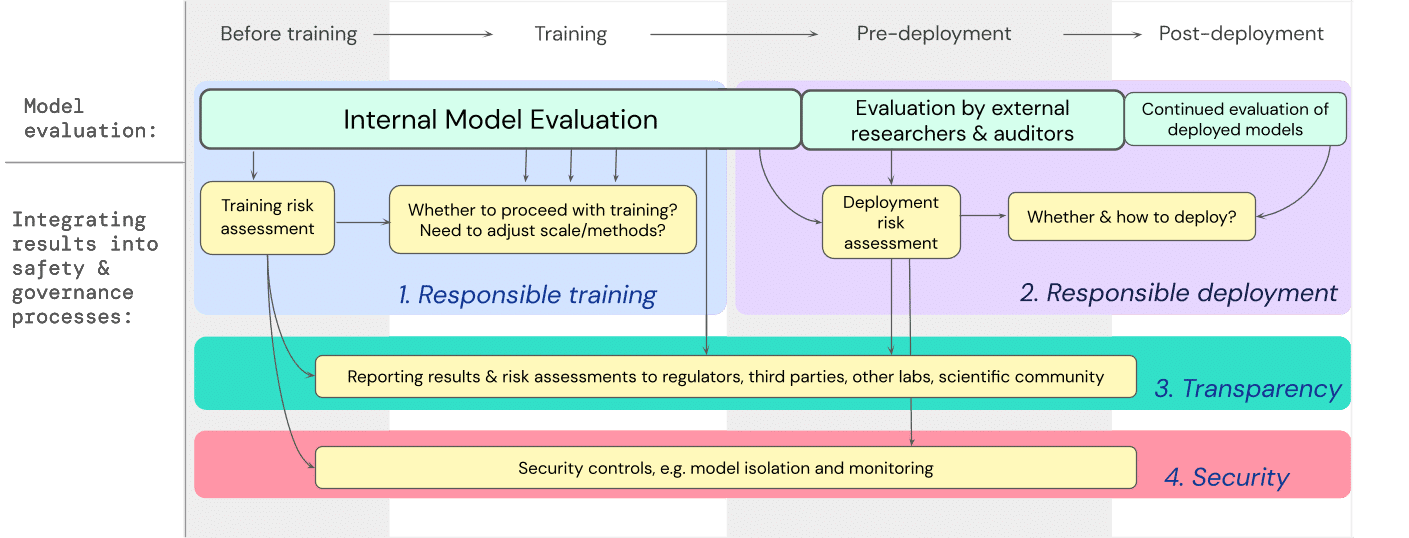
- 責任あるトレーニング:責任あるトレーニング:リスクの初期兆候を示す新しいモデルをトレーニングするかどうか、どのようにトレーニングするかについて、情報に基づいた決定を下すことができる。
- 責任を持って配備する:潜在的に危険なモデルを展開するかどうか、いつ、どのように展開するかについて、情報に基づいた意思決定を行うことができる。
- 透明性:関係者と適切で有用な情報を共有することで、起こりうるリスクへの備えや軽減に役立てることができる。
- 適切なセキュリティ:深刻なリスクをもたらす可能性のあるモデルには、強固な情報セキュリティ・プロトコルとシステムを導入することができる。
開発者は、極限リスクモデルの評価が、高い能力を持つ汎用モデルの訓練や配備に関する重要な意思決定にどのように影響するかについて、包括的な計画を作成した。開発者は全体を通して評価を行い、構造化されたモデルへのアクセスは、追加の評価のために外部の安全研究者やモデル監査人に提供される。これらの評価は、モデルの訓練や配備に先立つリスク評価に影響を与えることになる。
今後の展開
極端なリスクに対するモデル評価の初期的な取り組みは、特にGoogle DeepMindなどで既に始まっている。しかし、すべての潜在的なリスクを特定し、新たな課題に対する保護を提供する評価プロセスを構築するためには、技術的にも制度的にもさらなる進展が必要だ。
モデルの評価は非常に重要だが、万能ではない。特に、社会、政治、経済の複雑なダイナミクスなどの外部要因に大きく依存している場合、特定のリスクが見落とされる可能性がある。モデル評価は、他のリスク評価ツールや、産業界、政府、市民社会全体の安全への取り組みと統合する必要がある。
責任あるAIに関するGoogleの最近のブログにあるように、「AIの導入を成功させるには、個人の実践、業界標準の共有、政府の強固な政策が不可欠」であることを強調している。AI分野の多くの人たちやその影響を受ける人たちが協力して、みんなの利益のためにAIを安全に作成・展開するための方法と基準を開発することが望まれているのだ。
モデルに出現した危険な特性を特定し、懸念される結果に適切に対応するプロセスの理解は、AI能力の最前線における責任あるAI開発の重要な側面である。
論文
参考文献
- Google DeepMind: An early warning system for novel AI risks
研究の要旨
汎用的なAIシステムを構築する現在のアプローチでは、有益な能力と有害な能力を併せ持つシステムが生み出される傾向にある。AI開発がさらに進むと、攻撃的なサイバー能力や強力な操作スキルなど、極端なリスクをもたらす能力を持つようになる可能性がある。極端なリスクに対処するために、モデル評価が重要である理由を説明する。開発者は、危険な能力(「危険な能力評価」)と、その能力を害に適用するモデルの傾向(「アライメント評価」)を識別できなければならない。これらの評価は、政策立案者やその他の利害関係者に情報を提供し、モデルの訓練、配備、セキュリティについて責任ある決定を下すために不可欠となる。





コメントを残す