Googleは、例えば「ある建造物が建設された由来」や、「画像に写っている自動車の製造年」など、これまでの画像検索では難しかった質問への回答に応えるために、大規模言語モデルを用いてその目的を達成する情報探索型視覚的質問応答フレームワーク“AVIS”について明らかにした。

最近の大規模言語モデル(LLM)の進歩により、画像のキャプション付けや視覚的な質問に対する回答といった、これまでは困難だったマルチモーダルな機能が有効になった。しかし、これらの視覚言語モデル(VLM)は、外部知識を必要とする複雑な実世界の視覚推論(「視覚情報探索」と呼ばれる)にはまだ苦戦している。
この制限に対処するため、Googleの研究者らは、Googleの誇る大規模言語モデルであるPALMとコンピュータ・ビジョン、Web検索、画像検索ツールを統合した“AVIS”と呼ばれる新しい手法を発表した。これらのツールを使って、AVISは動的フレームワークで言語モデルを使用し、視覚情報を自律的に検索する。
GoogleのAVISは人間から学ぶ
大規模言語モデルとツールを硬直した2段階のプロセスで組み合わせた従来のシステムとは異なり、AVISは計画と推論のためにそれらをより柔軟に使用する。これにより、リアルタイムのフィードバックに基づいて行動を適応させることができる。
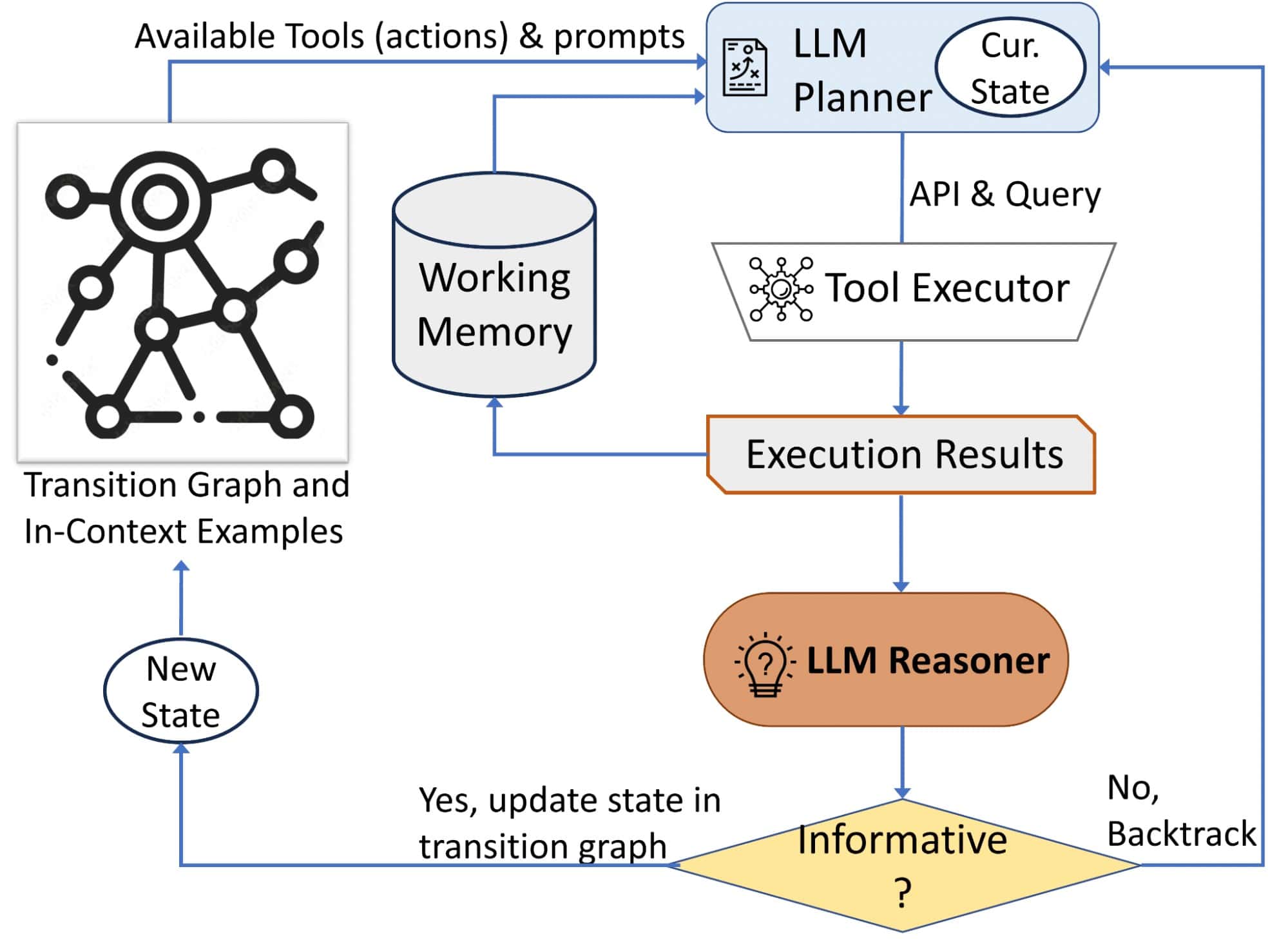
AVISには3つの主要コンポーネントがある:
- LLMを使用して次のアクション(APIコールとクエリー)を決定するプランナー
- 過去のAPI実行からの情報を保持するワーキングメモリー
- LLMを使ってAPIの出力を処理し、有用な情報を抽出する推論機能
- プランナーと推論器は反復的に使用され、プランナーは推論器からの更新された状態に基づいて次のツールとクエリーを決定する。これは、推論者が最終的な答えを提供するのに十分な情報があると判断するまで続けられる。
3種類のツールも統合されている:
- 画像から視覚情報を抽出するコンピュータ・ビジョン・ツール
- オープンワールドの知識や事実を検索するためのウェブ検索ツール
- 視覚的に類似した画像に関連するメタデータから関連情報を読み取る画像検索ツール
これらの機能をどのように活用するのが最適かを調べるため、研究者たちは視覚的推論ツールを使った人間の意思決定をとらえるユーザー調査を実施した。この研究により、AVISの動作をガイドする遷移グラフを構築するために使用される、一般的な一連の動作が明らかになった。

AVISは微調整なしで最先端の精度を達成
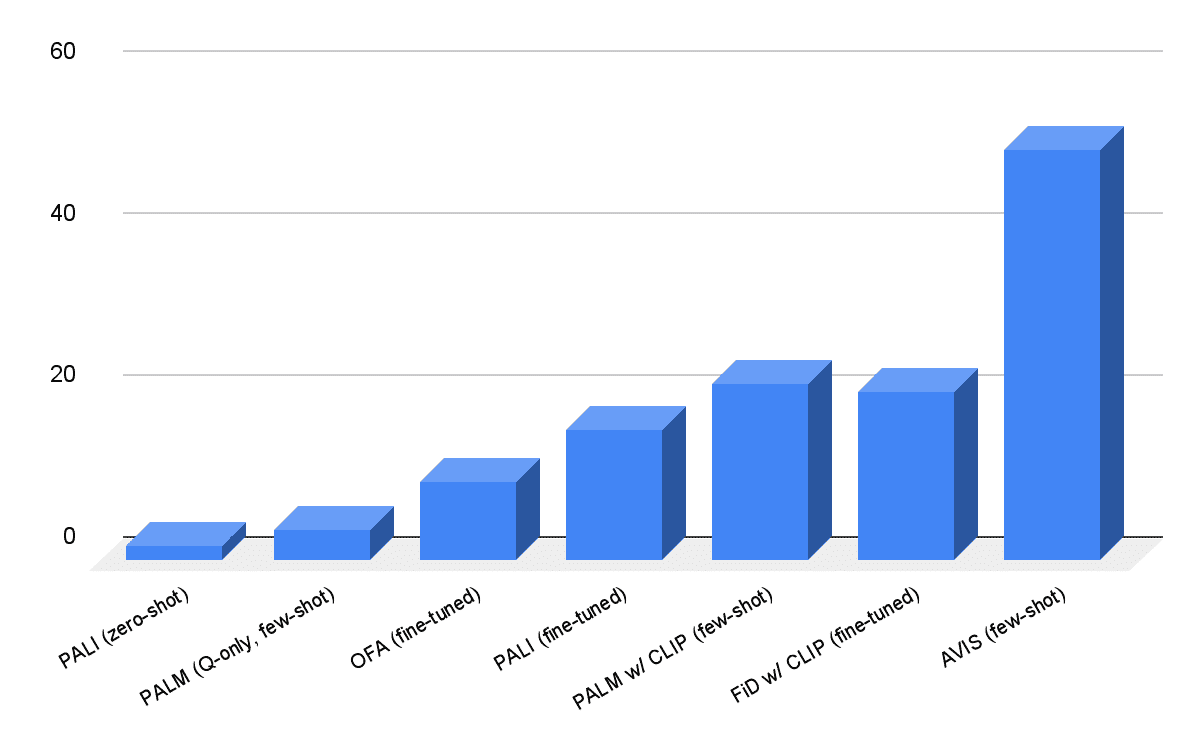
Infoseekデータセットにおいて、AVISは50.7%の精度を達成し、OFAやPaLIなどのファインチューニングされた視覚言語モデルを大きく上回った。OK-VQAデータセットでは、AVISは少ない例数で60.2%の精度を達成し、ほとんどの先行研究を凌駕し、ファインチューニングされたモデルに近づいたとGoogleは述べている。
将来的には、研究チームは他の推論タスクでこのフレームワークを探求し、より軽い言語モデルでこれらの機能を実行できるかどうかを確かめたいと考えている。
論文
参考文献
- Google Reseach: Autonomous visual information seeking with large language models
研究の要旨
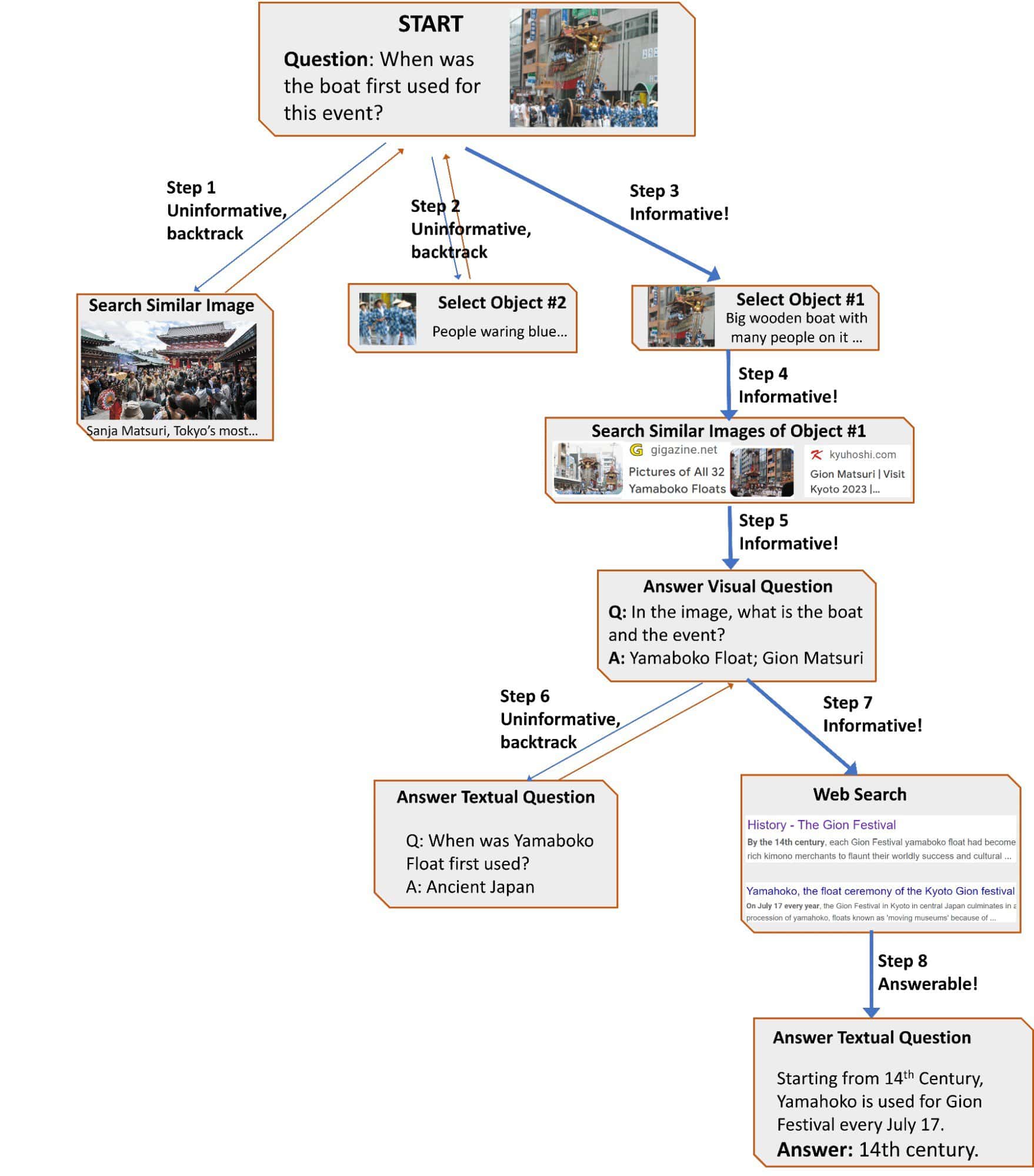
本稿では、自律的な情報探索型視覚的質問応答フレームワーク“AVIS”を提案する。本手法は、大規模言語モデル(Large Language Model: LLM)を活用して、外部ツールの利用を動的に戦略化し、その出力を調査することで、投げかけられた質問に対する回答を提供するために必要不可欠な知識を獲得する。例えば、「この画像に描かれている建物は、どのような出来事を記念しているのか」というような、外部知識を必要とする視覚的な質問に対する回答は、複雑なタスクである。このタスクは、APIを呼び出し、その応答を分析し、情報に基づいた決定を下すといった一連の動作を要求する、組み合わせ検索空間を提示する。我々は、このタスクに直面したときの人間の意思決定に関する様々な事例を収集するために、ユーザー調査を実施する。このデータは、次にどのツールを使用するかを動的に決定するLLMを搭載したプランナー、ツールの出力から重要な情報を分析・抽出するLLMを搭載した推論器、プロセス全体を通して取得した情報を保持する作業記憶コンポーネントの3つのコンポーネントで構成されるシステムを設計するために使用される。収集されたユーザーの行動は、次の2つの重要な点で、私たちのシステムの指針となる。2つの重要な方法がある。まず、ユーザーによる一連の意思決定を分析し、遷移グラフを作成する。このグラフは、異なる状態を定義し、各状態で利用可能なアクションを限定する。各状態で利用可能なアクションのセットを限定する。第二に、我々はユーザーの意思決定の例を用いて、LLMを搭載したプランナーと推論者に関連する文脈的な事例を提供し、情報に基づいた意思決定を行う能力を強化する。我々は、AVISがInfoseek [7]やOK-VQA [26]のような知識集約的な視覚的質問応答ベンチマークにおいて、最先端の結果を達成したことを示す。





コメントを残す